Python |
您所在的位置:网站首页 › wordcloud stopwords 中文 › Python |
Python
|
一 jieba jieba是基于python的中文分词工具 github:https://github.com/fxsjy/jieba 开源中国地址:https://www.oschina.net/p/jieba/?fromerr=LRXZzk9z 二 jieba的四种分词模式精确模式:试图将句子最精确地分开,适合文本分析。全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。与精准模式相比就是cut_all=True。搜索模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。paddle模式:引擎利用了PaddlePaddle的软件,分词速度比精确快。需要jieba到0.4版本以后才支持paddle模式。jieba主要使用的是cut方法,当使用搜索引擎模式的时候为cut_for_search。cut_all模式用来控制是否采用全量模式。 jieba.cut和jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语,或者使用: jieba.lcut和jieba.lcut_for_search直接返回list import jieba # jieba.enable_paddle() # 0.4版本以后支持paddle模式 strings = ['我来自中国', '我来到北京清华大学'] for string in strings: result = jieba.cut(string, cut_all=False) # 精确模式 print('Default Mode: ' + '/'.join(list(result))) for string in strings: result = jieba.cut(string, cut_all=True) # 全模式 print('Full Mode: ' + '/'.join(list(result))) for string in strings: result = jieba.cut(string, use_paddle=True) # paddle模式 print('Paddle Mode: ' + '/'.join(list(result))) result = jieba.cut('钟南山院士接受采访新冠不会二次暴发') # 默认是精确模式 print('/'.join(list(result))) # "新冠" 没有在词典中,但是被Viterbi算法识别出来了 result = jieba.cut_for_search('小明硕士毕业于中国科学院计算所,后在日本京都大学深造') # 搜索引擎模式 print('Search Mode: ' + '/'.join(list(result))) 三 关键词抽取基于TF-IDF算法的关键词抽取import jieba.analyse
import pprint #pprint 模块提供了打印出任何Python数据结构的类和方法
text = '机器学习,需要一定的数学基础,需要掌握的数学基础知识特别多,如果从头到尾开始学,估计大部分人来不及,我建议先学习最基础的数学知识'
# 基于TF-IDF算法进行关键词抽取
tfidf = jieba.analyse.extract_tags(text,
topK=5, # 权重最大的topK个关键词,默认值为 20
withWeight=True) # 返回每个关键字的权重值
pprint.pprint(tfidf) 三 关键词抽取基于TF-IDF算法的关键词抽取import jieba.analyse
import pprint #pprint 模块提供了打印出任何Python数据结构的类和方法
text = '机器学习,需要一定的数学基础,需要掌握的数学基础知识特别多,如果从头到尾开始学,估计大部分人来不及,我建议先学习最基础的数学知识'
# 基于TF-IDF算法进行关键词抽取
tfidf = jieba.analyse.extract_tags(text,
topK=5, # 权重最大的topK个关键词,默认值为 20
withWeight=True) # 返回每个关键字的权重值
pprint.pprint(tfidf) 基于 TextRank 算法的关键词抽取 基于 TextRank 算法的关键词抽取TextRank是从谷歌的PageRank中提取的到的 TF-IDF:词频-逆文件频率 DF低 IDF高 TF * IDF import jieba.analyse import pprint #pprint 模块提供了打印出任何Python数据结构的类和方法 text = '机器学习,需要一定的数学基础,需要掌握的数学基础知识特别多,如果从头到尾开始学,估计大部分人来不及,我建议先学习最基础的数学知识' # 基于TextRank算法进行关键词抽取 textrank = jieba.analyse.textrank(text, topK=5, # 权重最大的topK个关键词 withWeight=True) # 返回每个关键字的权重值 pprint.pprint(textrank) 四 停止词 四 停止词停止词只能支持关键字提取 import jieba import jieba.analyse text = '机器学习,需要一定的数学基础,需要掌握的数学基础知识特别多,如果从头到尾开始学,估计大部分人来不及,我建议先学习最基础的数学知识' stop_words=r'/root/test/python/tmp/pycharm_project_278/stopword.txt' # stop_words 的文件格式是文本文件,每行一个词语 jieba.analyse.set_stop_words(stop_words) textrank = jieba.analyse.textrank(text, topK=5, withWeight=False) import pprint # pprint 模块提供了打印出任何Python数据结构的类和方法 pprint.pprint(textrank)例:stopword.txt  需要 和 掌握 已经去掉 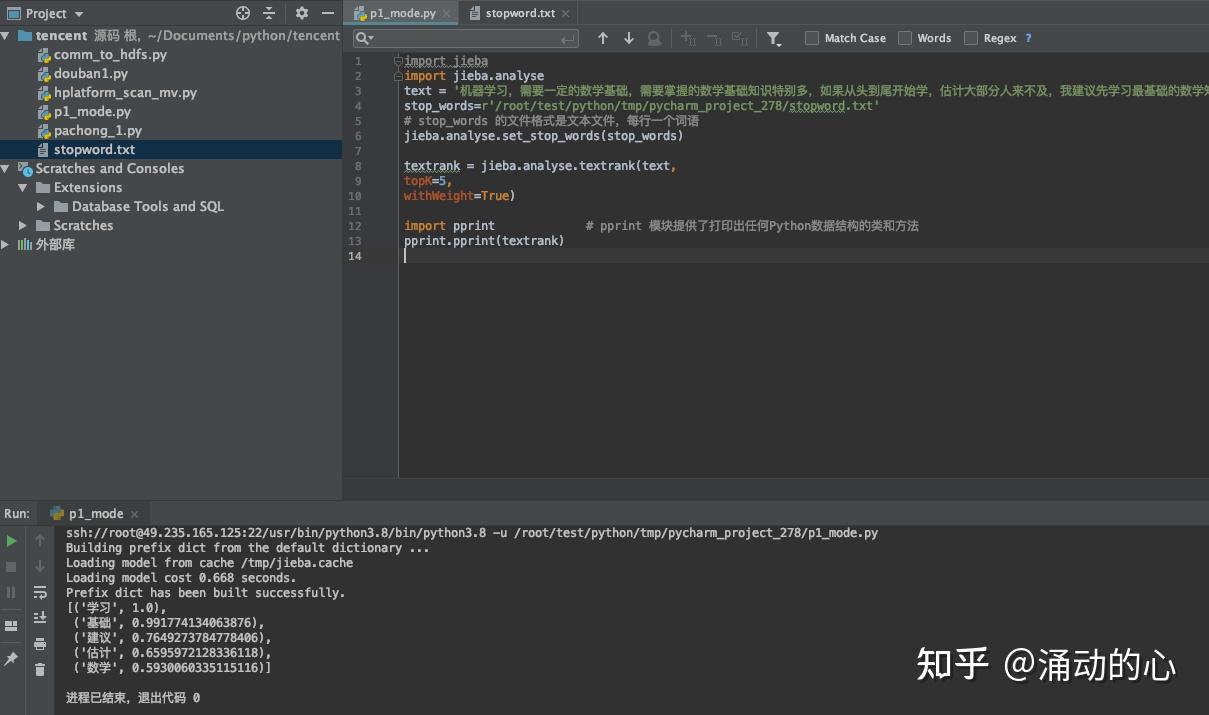 五 自定义词典 五 自定义词典通过自定义词典,确认词是否分开 字典分为静态词典和动态词典 HMM模型:隐马尔可夫模型 import jieba string = '北京欢乐谷玩的地方还挺多' user_dict=r'/root/test/python/tmp/pycharm_project_278/user_dict.txt' # 自定义词典 jieba.load_userdict(user_dict) result = jieba.cut(string, cut_all=False) print('自定义: ' + '/'.join(list(result))) # 动态添加词典 jieba.add_word('北京欢乐谷') # 动态删除词典 jieba.del_word('自定义词') result = jieba.cut(string, cut_all=False) print('动态添加: ' + '/'.join(list(result))) string2 = '我们中出了一个叛徒' result = jieba.cut(string2, cut_all=False) print('错误分词: ' + '/'.join(list(result))) print('=' * 40 ) # 关闭自动计算词频 result = jieba.cut(string2, HMM=False) print('关闭词频: ' + '/'.join(list(result))) # 调整分词,合并 jieba.suggest_freq('中出', True) result = jieba.cut(string2, HMM=False) print('分词合并: ' + '/'.join(list(result))) # 调整词频,被分出来 string3 = '如果放到Post中将出错' jieba.suggest_freq(('中','将'), True) result = jieba.cut(string3, HMM=False) print('分开分词: ' + '/'.join(list(result)))例:stopword.txt   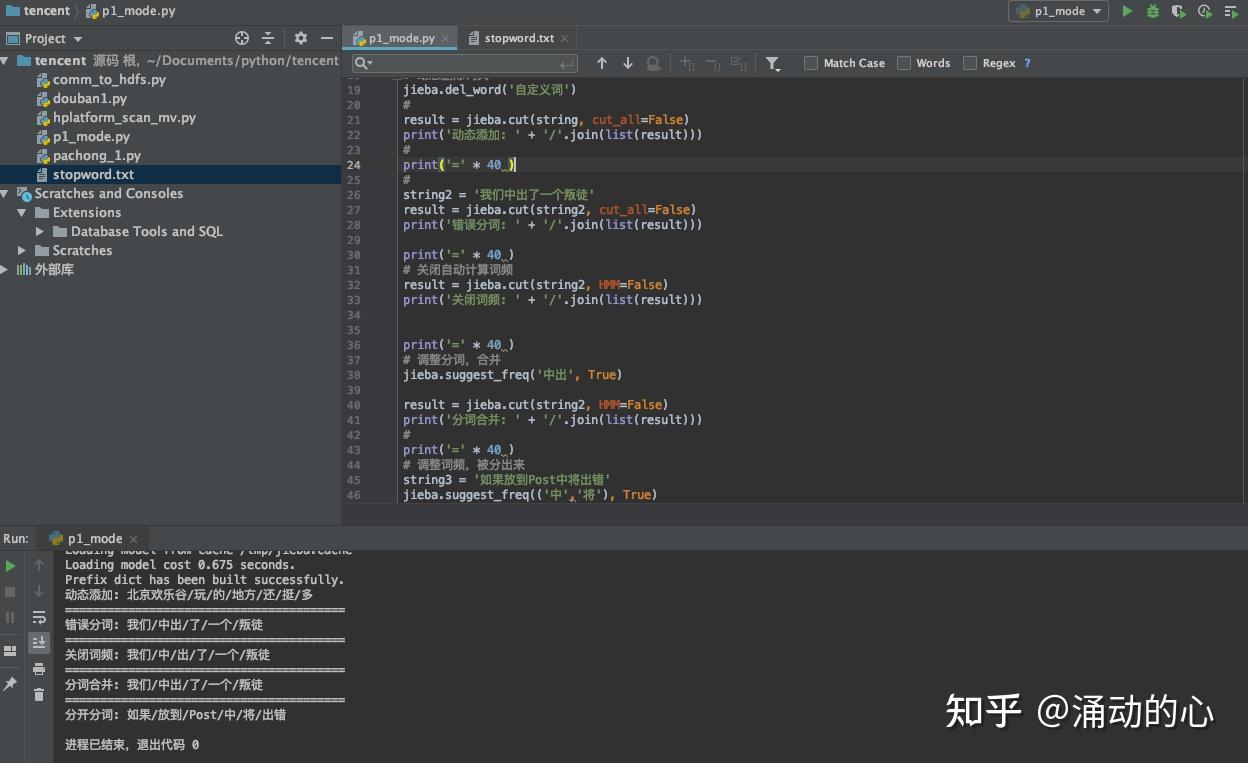 六 生成词云 六 生成词云在生成词云的过程中可能出现生成的为方框的情况,这是由于字体的原因导致的。 Windows环境或者Mac环境可以修改 wordcloud.py 中第30行的FONT_PATH 来进行调整。可以将FONT_PATH中的字体设置为:PingFang.ttc Linux环境下需要先通过:fc-list 命令查看是否有中文的字体,如果没有需要从本地导入。首先执行 yum -y install fontconfig命令,执行后会在/usr/share目录下创建font文件夹,然后查询本地机器的字体存在位置,上传到该文件夹下。  import numpy as np
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
from PIL import Image
from matplotlib import pyplot as plt
from matplotlib.pyplot import imread
import random
text_list = ['汤川', '东野', '短篇', '故事', '伽利略', '系列', '汤川学', '魔术', '神探', '扩写']
text_string = ','.join(text_list)
# 生成词云
wc = WordCloud(
width = 600, #默认宽度
height = 200, #默认高度
margin = 2, #边缘
ranks_only = None,
prefer_horizontal = 0.9,
mask = None, #背景图形,如果想根据图片绘制,则需要设置
color_func = None,
max_words = 200, #显示最多的词汇量
stopwords = None, #停止词设置,修正词云图时需要设置
random_state = None,
background_color = '#ffffff',#背景颜色设置,可以为具体颜色,比如:white或者16进制数值。
font_step = 1,
mode = 'RGB',
regexp = None,
collocations = True,
normalize_plurals = True,
contour_width = 0,
colormap = 'viridis',#matplotlib色图,可以更改名称进而更改整体风格
contour_color = 'Blues',
repeat = False,
scale = 2,
min_font_size = 10,
max_font_size = 200)
wc.generate_from_text(text_string)
# 显示图像
plt.imshow(wc, interpolation = 'bilinear')
plt.axis('off')
plt.tight_layout()
# 存储图像
wc.to_file('book1.png')
plt.show() import numpy as np
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
from PIL import Image
from matplotlib import pyplot as plt
from matplotlib.pyplot import imread
import random
text_list = ['汤川', '东野', '短篇', '故事', '伽利略', '系列', '汤川学', '魔术', '神探', '扩写']
text_string = ','.join(text_list)
# 生成词云
wc = WordCloud(
width = 600, #默认宽度
height = 200, #默认高度
margin = 2, #边缘
ranks_only = None,
prefer_horizontal = 0.9,
mask = None, #背景图形,如果想根据图片绘制,则需要设置
color_func = None,
max_words = 200, #显示最多的词汇量
stopwords = None, #停止词设置,修正词云图时需要设置
random_state = None,
background_color = '#ffffff',#背景颜色设置,可以为具体颜色,比如:white或者16进制数值。
font_step = 1,
mode = 'RGB',
regexp = None,
collocations = True,
normalize_plurals = True,
contour_width = 0,
colormap = 'viridis',#matplotlib色图,可以更改名称进而更改整体风格
contour_color = 'Blues',
repeat = False,
scale = 2,
min_font_size = 10,
max_font_size = 200)
wc.generate_from_text(text_string)
# 显示图像
plt.imshow(wc, interpolation = 'bilinear')
plt.axis('off')
plt.tight_layout()
# 存储图像
wc.to_file('book1.png')
plt.show()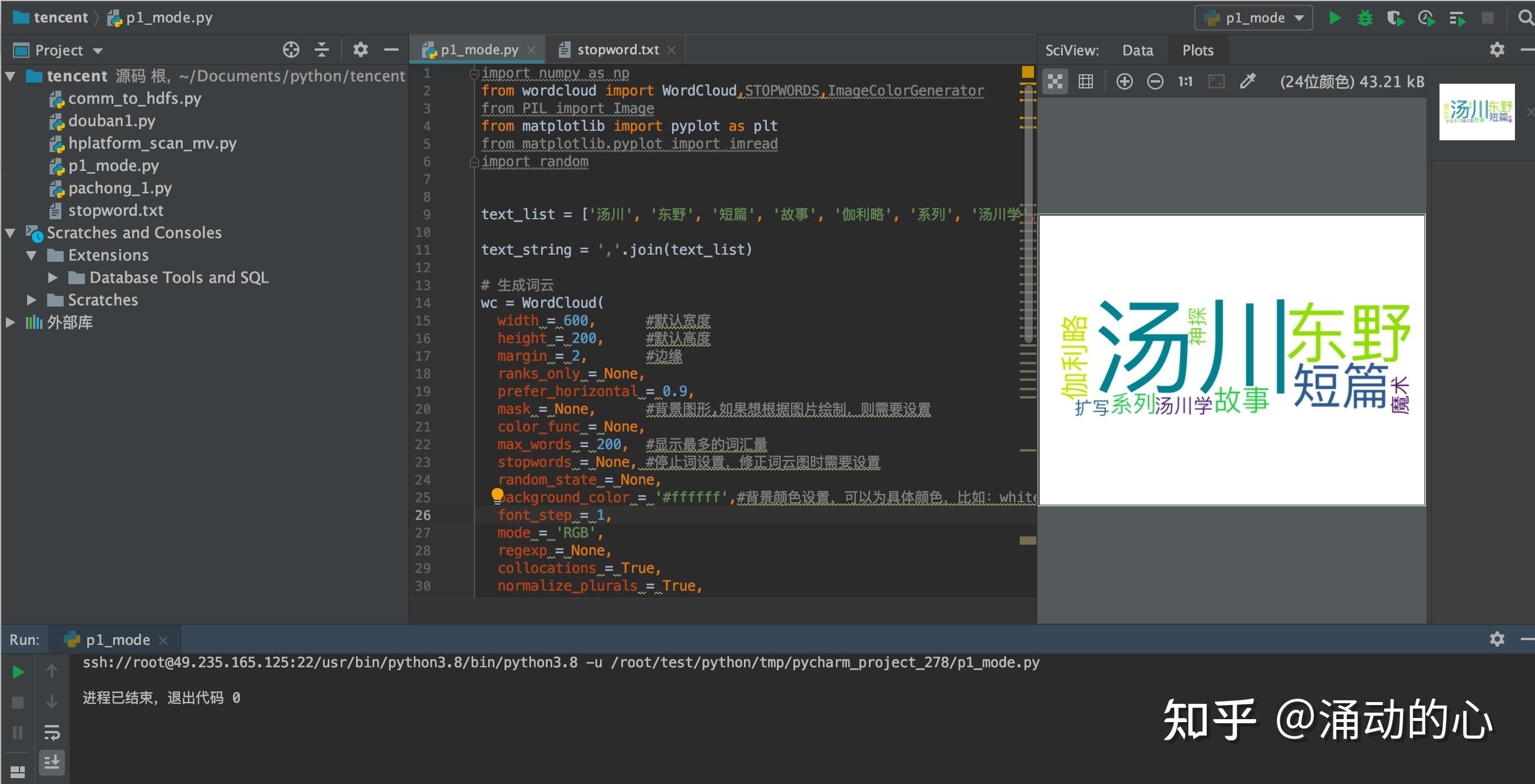
|
【本文地址】
今日新闻 |
推荐新闻 |